批量提交作业脚本
所需文件
#####批量提交脚本
#!/bin/bash
for file in ./*
do
if test -d $file
then
cp run.slurm $file
cd $file
chmod +x ./run.slurm && sbatch ./run.slurm
cd ..
sleep 1s
fi
done
提交脚本模板
#!/bin/bash
#SBATCH --nodes=1 # 节点数量
#SBATCH --ntasks-per-node=56 # 每个节点核心数量
#SBATCH --ntasks=56 # 总核心数
#SBATCH --partition=g1_cae # 队列分区且必须指定正确分区
#SBATCH --job-name=sp-b1 # 作业名称
#SBATCH --output=sp-b%a.out.%A # 正常日志输出 (%A 参数值为 jobId, %a 参数为inp文件的号)
#SBATCH --error=sp-b%a.err.%A # 错误日志输出 (%A 参数值为 jobId,%a 参数为inp文件的号)
#SBATCH -a 1-5 # 1-5 表示inp文件的区间
file=sp-b${SLURM_ARRAY_TASK_ID} # inp文件的格式前缀
echo "${file}.inp run in `hostname`"
echo "This is job #${SLURM_ARRAY_JOB_ID}, with parameter $SLURM_ARRAY_TASK_ID"
abaqus job=${file} input=${file}.inp analysis cpus=$SLURM_NPROCS scratch=$SLURM_SUBMIT_DIR interactive
sleep 1
操作步骤
1、将所有需要批量提交的算例放到一个文件夹下面的子文件夹中
结构示例:
 其中test2 为批量提交作业的文件夹,1-4代表提交作业子算例文件夹
2、将上述中第一个脚本放置在 test2 下默认为1.sh ,将准备好的算例提交脚本run.slurm 也放置在test2 下
结构示意:
其中test2 为批量提交作业的文件夹,1-4代表提交作业子算例文件夹
2、将上述中第一个脚本放置在 test2 下默认为1.sh ,将准备好的算例提交脚本run.slurm 也放置在test2 下
结构示意:
 3、执行 1.sh
source 1.sh
4、脚本解析
3、执行 1.sh
source 1.sh
4、脚本解析
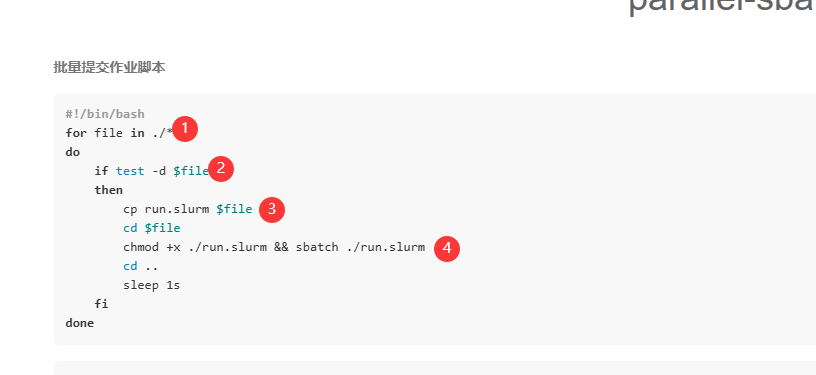
1 遍历当前文件夹下所有文件 2 判断是否为文件夹 3 复制提交脚本到子算例文件夹下 4 添加提交脚本执行权限 提交作业 注意: 一个子算例文件夹 放置一个算例 需要指定输入文件的 提交脚本 需要进行修改