业务管理
开发环境
“业务管理 > 开发环境”,在业务范围是训推、训练下可用
开发环境列表
单击左侧导航栏中的开发环境,打开开发环境列表页面,页面顶部展示开发环境汇总信息,列表中展示开发环境的基本信息,列表右侧展示相关操作按钮。 可以选中多个开发环境单击右上角删除按钮进行批量删除,或者单击任一开发环境右侧操作区域的下拉栏中的删除选项,如下:
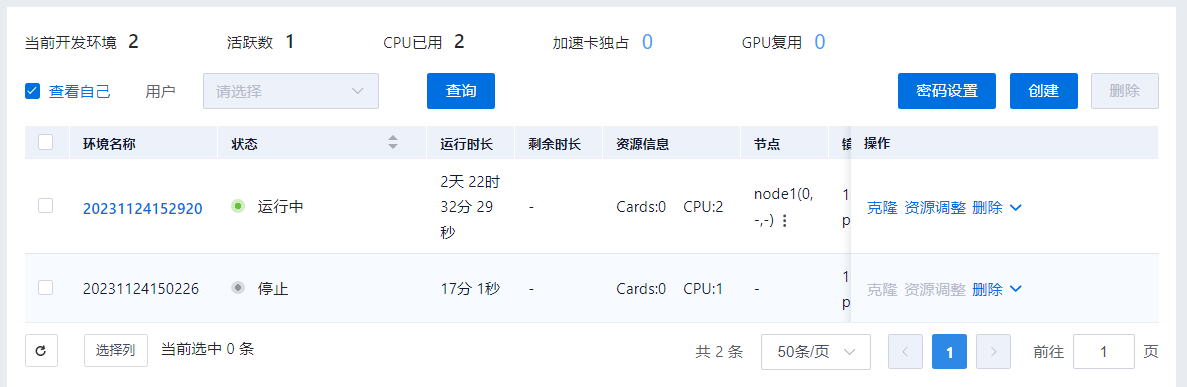
单击顶部密码设置按钮设置开发环境shell密码,支持随机密码(默认)、固定密码。
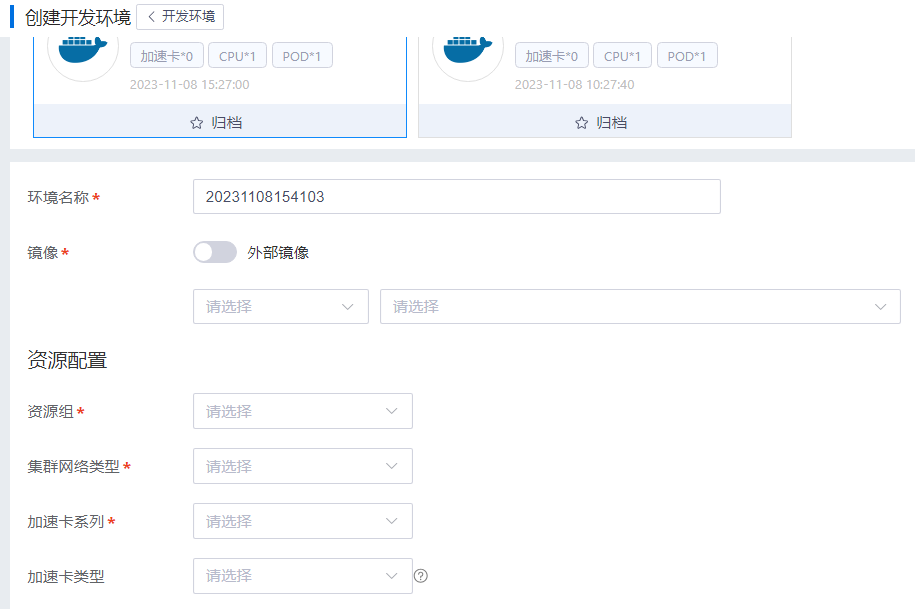
创建开发环境
用户单击页面中的创建按钮创建开发环境,支持从头创建开发环境(目前支持Caffe、TensorFlow、Mxnet、Pytorch、PaddlePaddle和other框架),也支持基于历史的开发环境创建,并可以将历史开发环境进行归档与取消归档,归档之后展示优先级提前, 用户可以选择资源组、资源配置、数据、模型、环境变量等信息,同时也可以指定节点,如下图:
开发环境详情
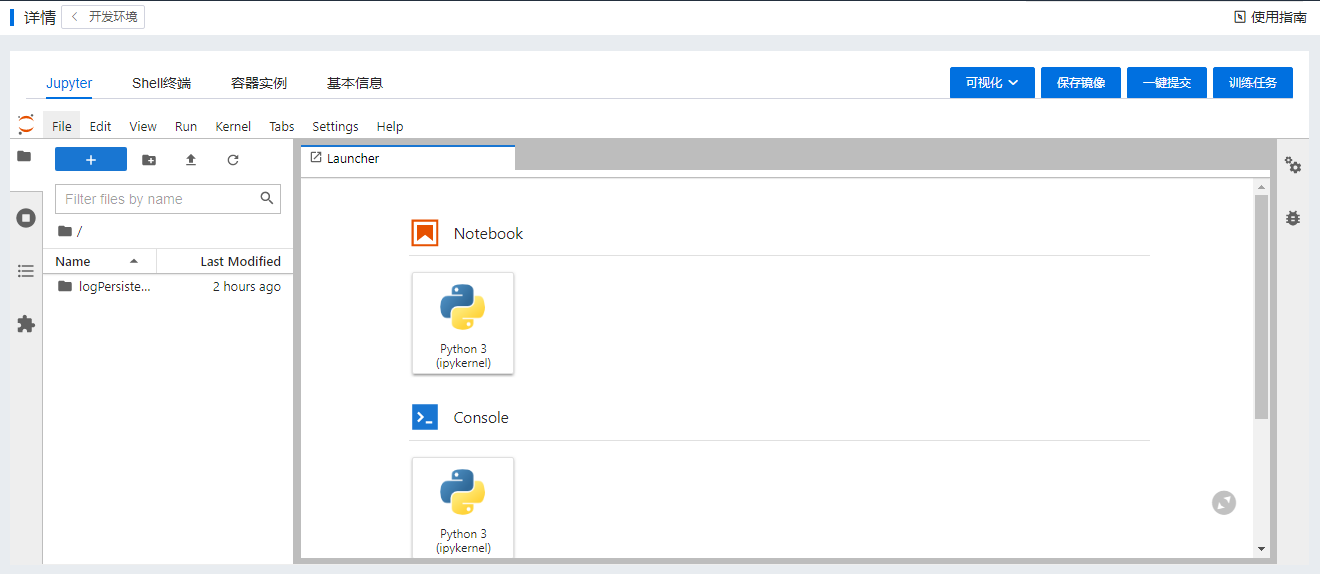
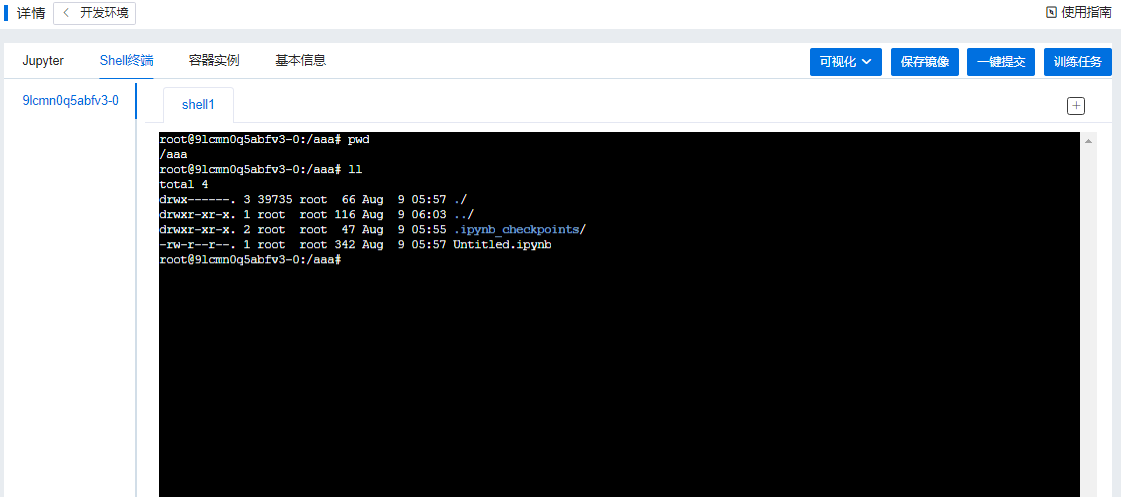
用户在开发环境列表中,单击运行中的开发环境的名称,可以进入该开发环境的详情中,在详情页中,可以使用Jupyter对脚本进行编辑调试, 可以使用web shell终端连接环境(支持多窗口),可以在容器实例中查看容器实例列表、性能监控,可以查看基本信息, 同时也支持可视化(目前支持TensorBoard、Visdom、Netscope)、将当前开发环境保存为镜像,一键提交训练任务,查看训练任务等功能,如下图:
Jupyter:
Shell终端:
容器实例:
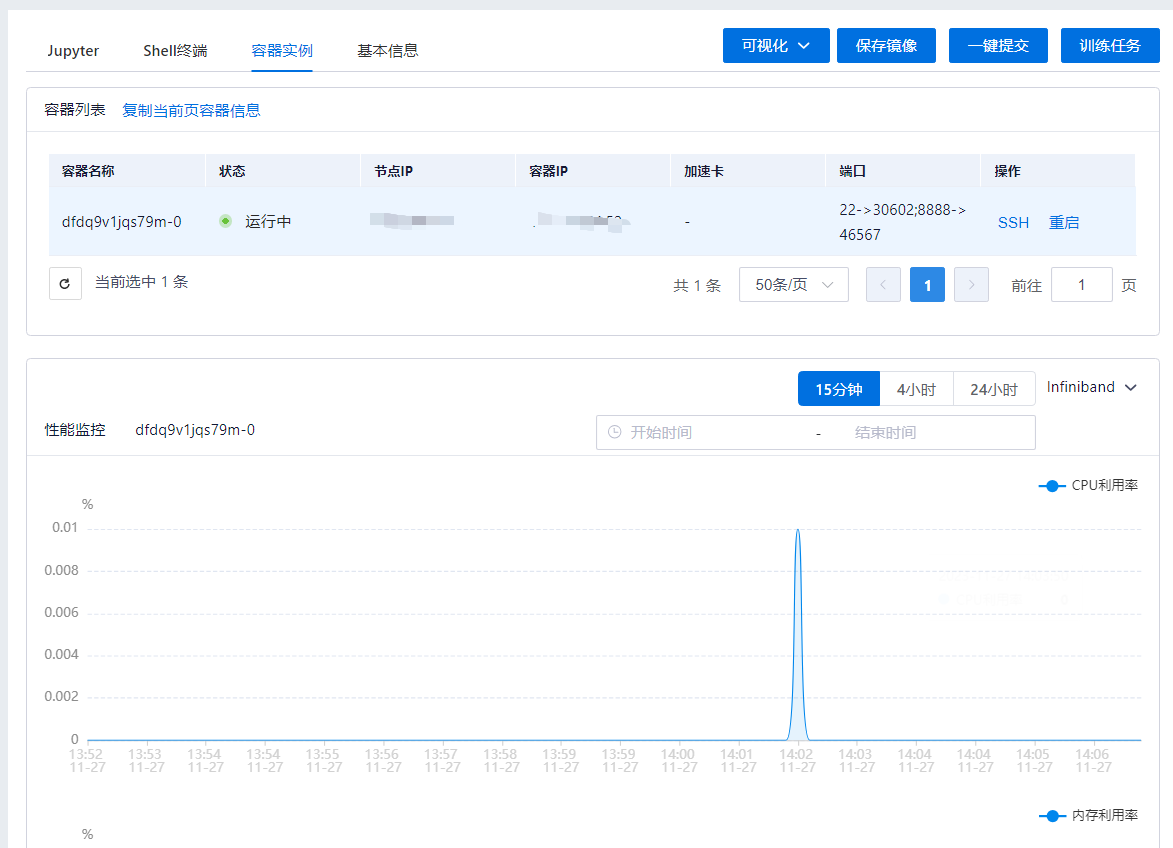
容器实例列表包括:名称、状态、加速卡、节点、IP、端口、操作列。
| 功能 | 描述 |
|---|---|
| 容器列表-复制当前页容器信息 | 通过该功能可以复制当前容器列表中(如果分页,需要切换分页才能复制其他页的数据)所有容器的Pod Name、节点IP、容器IP信息 |
| 操作列-SSH | 通过该功能可以复制连接相关容器的ssh命令、密码,注意,该功能需要相关镜像安装ssh组件 |
| 操作列-重启 | 通过该功能可以重启当前容器,如果出现个别容器启动失败,后续修复问题,可以通过该功能重启容器,不需要重启整个开发环境 |
性能曲线可以通过单击容器实例列表选择展示对应容器实例的数据,可以通过单击“15分钟”、“4小时”、“24小时”、自定义时间限制查询时间范围,如果容器所在节点使用了IB或RoCE网络可以通过“Infiniband”弹框筛选性能曲线中展示的对应网卡。
性能曲线指标包括:
| 场景 | 性能曲线指标 |
|---|---|
| 基本场景 | CPU利用率、内存利用率、网络输入/输出、内存总量/已用、磁盘输入/输出 |
| 使用GPU场景 | 基本场景下新增:加速卡利用率、加速卡显存利用率、加速卡显存已用、加速卡显存未用、draw_active、fp64_active、fp32_active、fp16_active、gr_engine_active、sm_active、sm_occupancy、tensor_active、pcie_rx_bytes、pcie_tx_bytes、nvlink_rx_bytes、nvlink_tx_bytes |
| 使用MIG场景 | 基本场景下新增:MIG显存利用率、MIG显存已用、MIG显存未用、draw_active、fp64_active、fp32_active、fp16_active、gr_engine_active、sm_active、sm_occupancy、tensor_active |
| 使用IB或RoCE网络场景 | 基本场景下新增:ib_xmitdata、ib_rcvdata、ib_xmitpktsize、ib_rcvpktsize |
注意:仅支持NVIDIA DCGM Profiling Metrics的GPU型号才会展示如下性能指标:gr_engine_active、sm_active、sm_occupancy、tensor_active、dram_active、fp16_active、fp32_active、fp64_active、pcie_rx_bytes、pcie_tx_bytes、nvlink_rx_bytes、nvlink_tx_bytes
基本信息:
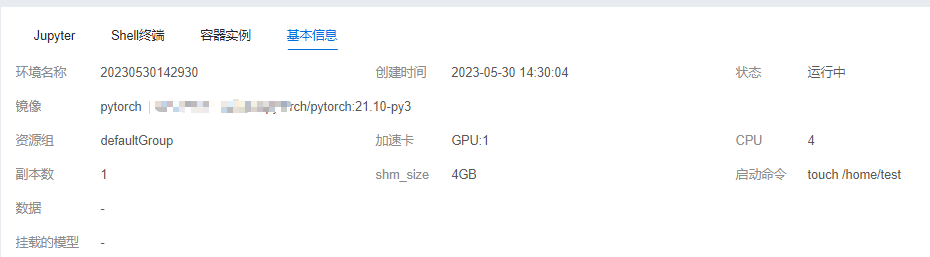
其他功能,包括可视化、保存镜像、一键提交、训练任务。
| 功能 | 描述 |
|---|---|
| 可视化 | 打开一个可视化环境,目前支持TensorBoard、Visdom、Netscope |
| 保存镜像 | 将当前开发环境中所有信息保存为一个新的镜像,类似docker commit 方式 |
| 一键提交 | 按照当前开发环境的配置,一键提交一个训练任务 |
| 训练任务 | 当前用户未完结训练任务的简易列表 |
开发环境操作功能
用户在列表中的操作栏中,可以对开发环境进行操作,目前支持以下操作:
| 功能 | 描述 |
|---|---|
| 克隆 | 克隆一个相同配置的开发环境 |
| 启动 | 将停止的开发环境启动 |
| 停止、恢复 | 用户可以将一个运行中的开发环境停止(停止后底层数据会删除),单击恢复后可以重新运行该开发环境 |
| 删除 | 可以删除开发环境 |
| 挂载数据集 | 可以挂载数据集 |
| 资源调整 | 可以对运行中的开发环境进行动态资源调整,修改资源配置 |
| 导出 | 可以导出当前开发环境的配置信息,按照一个副本一行的格式,每行的数据包括pod name、node ip、pod ip,保存到用户家目录中 |
任务管理
“业务管理 > 任务管理”,在业务范围是训推、训练下可用
创建训练任务
本手册以tensorflow单机任务为例子进行说明。 功能说明:用户通过平台提供的训练任务功能,能够自动创建一个新的训练任务,创建成功后自动在任务管理列表展示该任务。
操作步骤:
A:进入“业务管理 > 任务管理”,单击页面“创建”按钮,弹出填写任务信息页面,如下图:
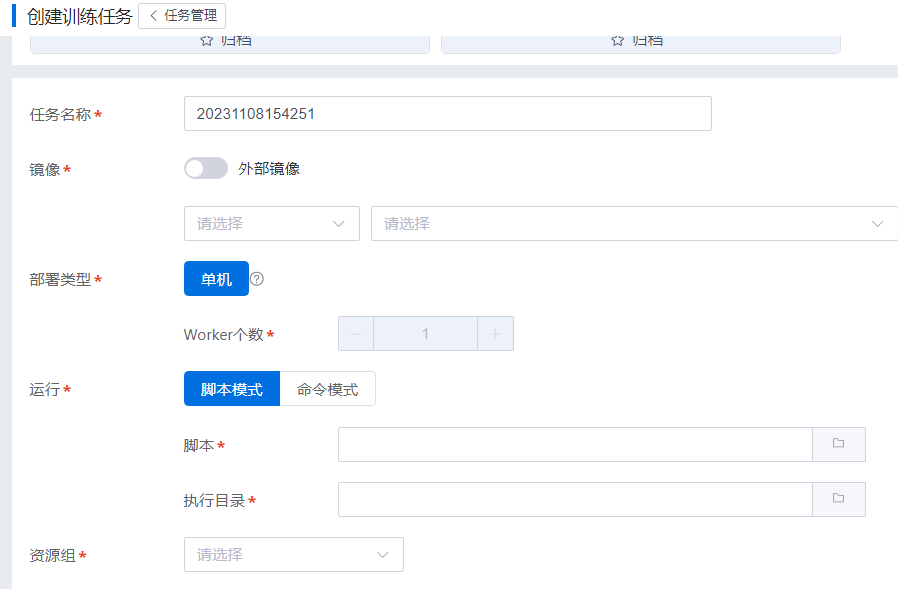
B:填写任务详细信息:
名称:任务名字(只接受英文字母、数字和下划线,不能以下划线开头)。
镜像:在第一个窗口选择tensorflow框架名称,在第二个窗口选择框架版本。
外部镜像:勾选该选项后,用户可以自定义输入镜像名称。
部署类型:训练任务部署类型,选择“单机”。
资源组:选择资源组。
网络类型:选择相应网络类型。
加速卡系列:根据下拉列表配置可选择相应的加速卡系列;只能使用一种类型提交任务;右侧的可用节点信息会根据所选加速卡系列,进行动态筛选变化。
加速卡类型:选择资源组内相应的加速卡类型。
CPU/加速卡:选择Worker节点的CPU/加速卡资源配置方案,当配额方案是“自定义”时,会弹出加速卡和CPU窗口,可以自定义设置资源配置方案。
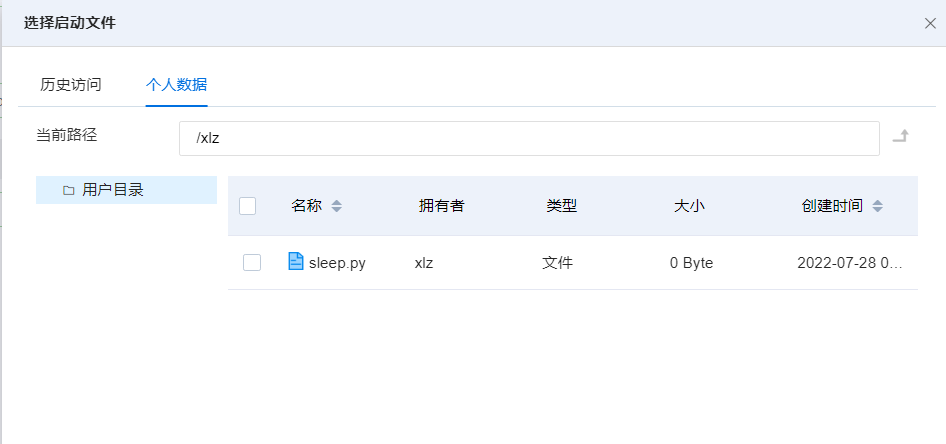
脚本:单击窗口后的按钮,弹出“选择启动文件”窗口,选择tensorflow单机训练脚本。
脚本示例路径:/xlz/models/tensorflow/mnist/tf_mnist_single.py
说明:xlz这个表示用户的家目录,最终以实际的用户名为准;选定后单击确定。
“选择启动文件”中有两个子选项,分别为 “历史访问”、“个人数据”。“历史访问”表示以前使用过的启动脚本,展示在此处以便用户选择。“个人数据”表示自己文件中的数据文件。
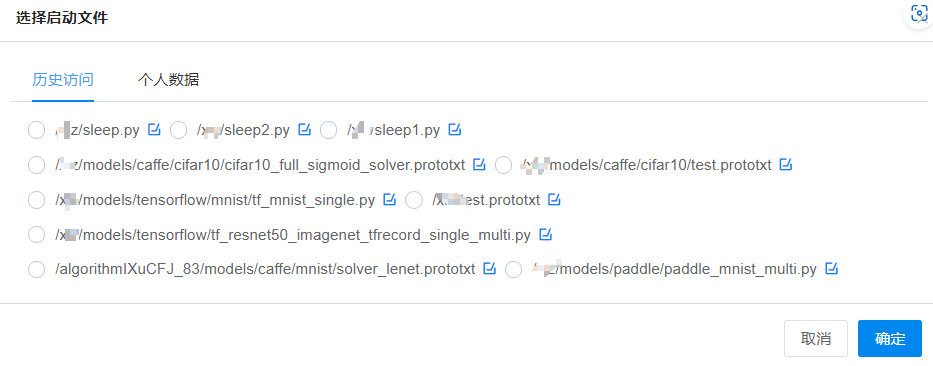
命令:用户单击“命令模式”会切换到命令模式,可以自定义自己的启动命令。
执行目录:选择执行训练脚本的目录,执行目录可以选择自己目录下的任何文件夹。
脚本参数:在“脚本参数”输入框可以输入python脚本所跟随的参数,例如“--data_dir /MNIST_data --data_dir2 /MNIST_data2”
弹性任务配置:
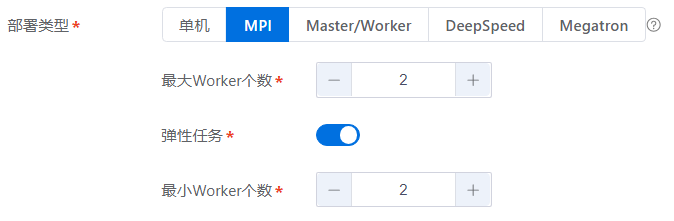
目前训练框架支持Horovod+Tensorflow, Horovod+Pytorch, Pytorch DDP方式的弹性任务。
用户单击“弹性任务”开启,设置“最大Worker个数”大于“最小Worker个数”,完成弹性任务配置。
1.MPI弹性任务,增加命令参数:--host-discovery-script /etc/mpi/discover_hosts.sh,命令参数示例
horovodrun --verbose -np 2 --min-np 2 --max-np 4 --blacklist-cooldown-range 120 300 --host-discovery-script /etc/mpi/discover_hosts.sh python train.py
2.Pytorch弹性任务,命令参数示例
torchrun --nnodes=2:4 --nproc_per_node=1 --max_restarts=100 --rdzv_id=1 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR":"$MASTER_PORT python train.py

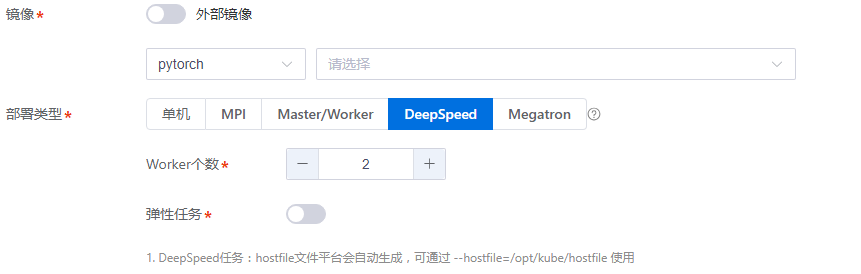
大模型分布式任务:
在镜像框架选择为Pytorch时,平台提供DeepSpeed、Megatron两个大模型框架。
在DeepSpeed框架下,平台自动生成hostfile文件,训练脚本可指定参数--hostfile=/opt/kube/hostfile启动训练。
在Megatron框架下,平台会启动一个master和页面参数指定个数的worker,在容器内自动设置MASTER_ADDR、MASTER_PORT、RANK等环境变量。训练程序可以直接使用环境变量启动训练。
数据配置: 单击“数据配置 > 数据”,提供2种数据配置方式:
数据-文件管理
在弹出的路径选择窗口中选择要使用的数据集,支持选择多个数据集。
数据-数据集管理
在数据集列表中选择可用数据集,只能选择一个数据集。
更新数据集说明:勾选后,平台自动会对缓存的数据集进行识别,如果部分数据集文件发生变化,平台会实现增量更新,如果缓存中没有数据集,会全量下载数据集。如果缓存中的数据集正在使用,则不能进行更新操作。
数据集使用方式说明:有“节点缓存”和“直接使用”两种方式。“节点缓存”表示将数据集缓存到节点,“直接使用”表示使用共享存储中的数据集。
注意:数据集也可以来自于用户目录、公共目录(全局共享和组共享),数据集可以选择多个。数据集示例路径:/MNIST_data
解压数据集说明:只有节点缓存方式支持解压操作,解压支持递归解压,解压类型支持:tar、tar.gz、zip、gz、tar.bz2,解压目录和压缩包目录同级且同名,解压支持单个数据集操作。
选择模型:用户可选择需要挂载的模型。
环境变量:用户可添加自定义环境变量。
更多配置:
| 功能 | 描述 |
|---|---|
| 调度策略 | 配置调度策略,目前支持spread(默认)、bestfit。 |
| 端口 | 提供服务端口访问能力,容器内服务端口会自动映射到宿主机的端口上,且支持多个端口设置,多端口之间用英文状态下的分号隔开,第一个端口具有容错能力,其他端口只提供服务功能。设置完成后,可以在实例列表中查看到对应的端口信息。 |
| 内存 | 配置训练任务Worker节点所需要的内存,当设置为0时表示无限制(需要小于Worker所在主机目前剩余内存量)。 |
| 日志路径 | 训练日志输出路径,单击窗口后的按钮,选择相应路径后单击“确定”。 |
| 目录挂载 | 可供挂载的公共目录。 |
| shm_size | 容器shm_size参数,默认为4GB。 |
在右侧区域显示资源组下的节点信息,这里可以自定义运行的节点,比如需要在ainode53上运行该任务,可以直接勾选,这样平台会默认调度到该节点上。节点列表中还可以看到每个节点上资源的情况。如果不选择节点,则平台会自动选择剩余资源满足的节点运行该任务。
C:信息填写完之后,单击“确定”按钮创建任务,任务展示在任务管理列表中。
停止训练任务
功能说明:用户通过平台提供的停止训练任务功能,能够停止一个正在运行的训练任务。工作流相关类型的任务不支持该操作。
操作步骤:
A:进入“业务管理 > 任务管理”,选中一个正在运行的训练任务,单击“停止”按钮。
B:页面显示停止成功表示该操作成功。
启动训练任务
功能说明:用户通过平台提供的启动训练任务功能,能够启动一个停止的训练任务。工作流相关类型的任务不支持该操作。
操作步骤:
A:进入“业务管理 > 任务管理”,选中一个停止的训练任务,单击“启动”按钮。
B:任务重新启动说明操作成功。
重新提交训练任务
功能说明:用户通过平台提供的重新提交训练任务功能,能够重新提交一个训练任务。工作流相关类型的任务不支持该操作。
操作步骤:
A:进入“业务管理 > 任务管理”,选中一个训练任务,单击“重新提交”按钮。
通过历史记录提交训练任务
功能说明:用户通过平台提供的通过历史记录提交训练任务功能。
操作步骤:
A:进入“业务管理 > 任务管理”,单击“创建”按钮,进入任务信息填写窗口,如下图: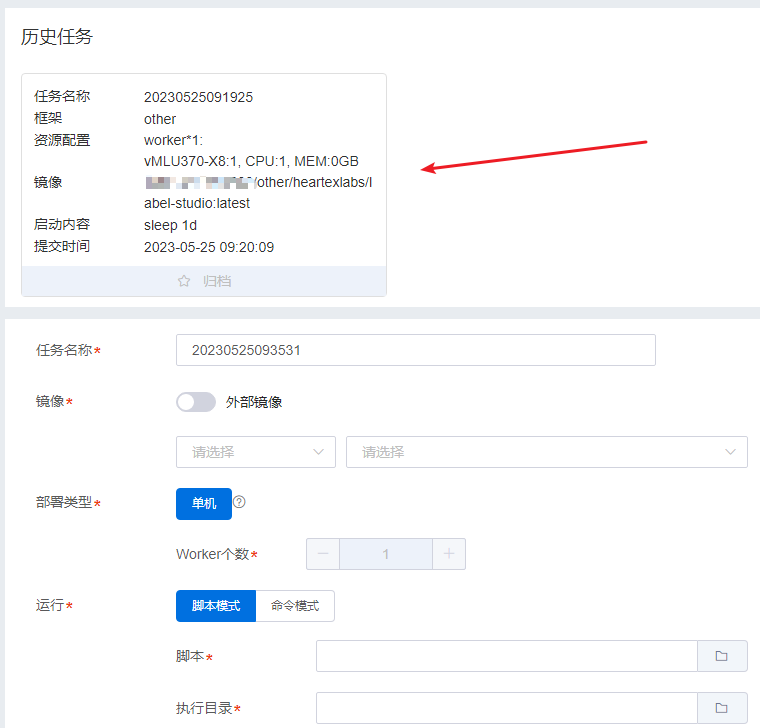
B:可以将历史任务进行归档与取消归档,归档之后展示优先级提前。
C:选中相应的历史任务后,单击后将自动填充历史任务信息:框架类型、镜像、加速卡、CPU、内存、启动文件、数据集等信息。
删除训练任务
功能说明:用户通过平台提供的删除训练任务功能,能够删除一个训练任务。工作流相关类型的任务不支持该操作。
操作步骤:
A:进入“业务管理 > 任务管理”,选中一个训练任务,单击“删除”按钮。
B:页面显示删除成功表示该操作成功。
筛选未终结任务
功能说明:用户通过筛选功能筛选未终结的任务。
操作步骤:
A:进入“业务管理 > 任务管理”,单击“任务管理”列表,通过筛选功能进行筛选。
筛选终结任务
功能说明:用户通过筛选功能筛选终结的任务。
操作步骤:
A:进入“业务管理 > 任务管理”,单击“终结任务”列表,通过筛选功能进行筛选。
查看训练日志
功能说明:用户通过平台提供的查看任务日志功能,能够查看具体的训练日志。
操作步骤:
A:进入“业务管理 > 任务管理”,单击任务名字跳转到任务详情页面,单击“任务日志”按钮可以查看训练日志。
查看容器实例
功能说明:用户通过平台提供的查看任务容器实例功能,能够查看任务的容器实例信息和监控信息。
操作步骤:
A:进入“业务管理 > 任务管理”,单击任务名字跳转到任务详情页面,单击“容器实例”按钮可以查看容器实例信息,如下图:
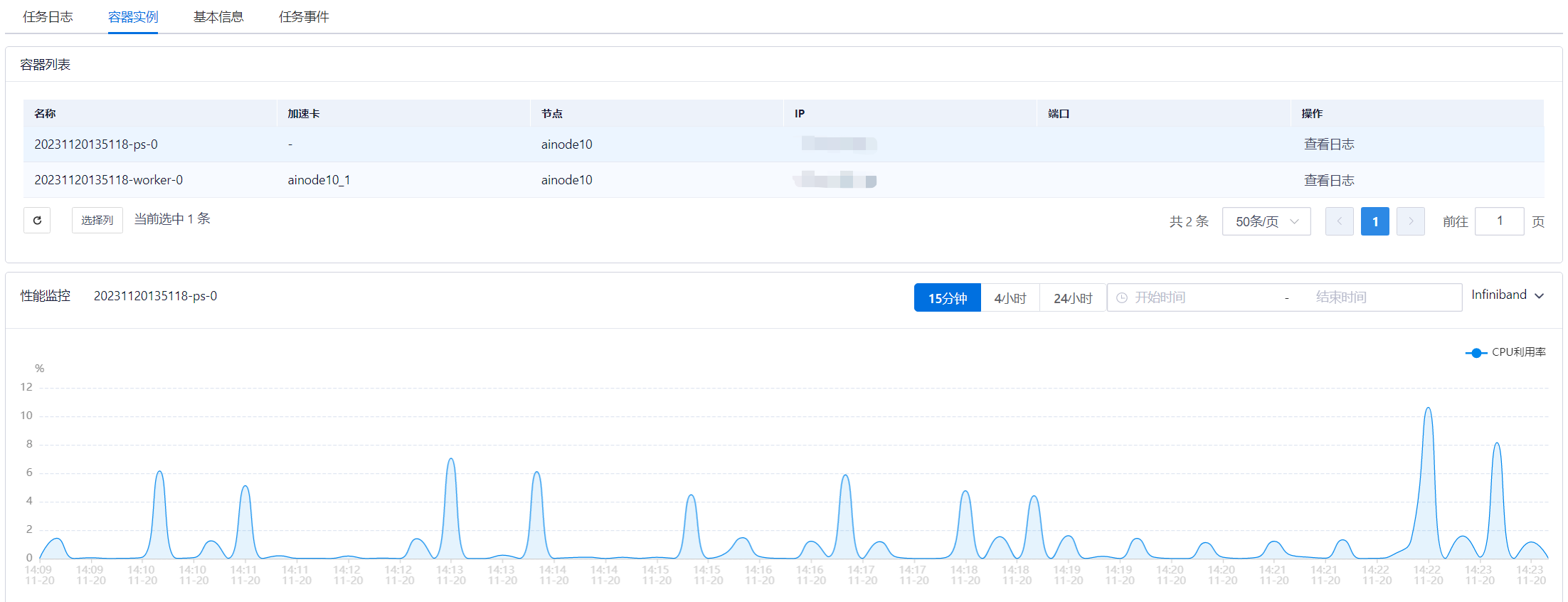
容器实例列表包括:名称、状态、加速卡、节点、IP、端口、操作列。
性能曲线可以通过单击容器实例列表选择展示对应容器实例的数据,可以通过单击“15分钟”、“4小时”、“24小时”、自定义时间限制查询时间范围,如果容器所在节点使用了IB或RoCE网络可以通过“Infiniband”弹框筛选性能曲线中展示的对应网卡。
性能曲线指标包括:
| 场景 | 性能曲线指标 |
|---|---|
| 基本场景 | CPU利用率、内存利用率、网络输入/输出、内存总量/已用、磁盘输入/输出 |
| 使用GPU场景 | 基本场景下新增:加速卡利用率、加速卡显存利用率、加速卡显存已用、加速卡显存未用、draw_active、fp64_active、fp32_active、fp16_active、gr_engine_active、sm_active、sm_occupancy、tensor_active、pcie_rx_bytes、pcie_tx_bytes、nvlink_rx_bytes、nvlink_tx_bytes |
| 使用MIG场景 | 基本场景下新增:MIG显存利用率、MIG显存已用、MIG显存未用、draw_active、fp64_active、fp32_active、fp16_active、gr_engine_active、sm_active、sm_occupancy、tensor_active |
| 使用IB或RoCE网络场景 | 基本场景下新增:ib_xmitdata、ib_rcvdata、ib_xmitpktsize、ib_rcvpktsize |
注意:仅支持NVIDIA DCGM Profiling Metrics的GPU型号才会展示如下性能指标:gr_engine_active、sm_active、sm_occupancy、tensor_active、dram_active、fp16_active、fp32_active、fp64_active、pcie_rx_bytes、pcie_tx_bytes、nvlink_rx_bytes、nvlink_tx_bytes
查看任务基本信息
功能说明:用户通过平台提供的查看任务基本功能,能够查看任务的基本信息。
操作步骤:
A:进入“业务管理 > 任务管理”,单击任务名字跳转到任务详情页面,单击“基本信息”按钮可以查看任务基本信息。
任务可视化
功能说明:用户通过平台提供的可视化功能,能够查看任务的训练日志。
操作步骤:
A:进入“业务管理 > 任务管理”,在任务列表的操作栏,单击“可视化”按钮。
B:如果在创建任务的时候没有选择日志路径,在此处将会再次提示用户选择。
C:单击“确定”后,弹出可视化窗口。
提交紧急任务
如果用户有提交紧急任务的权限,当单击“创建”按钮,创建任务时,可以看到紧急任务的开关。
开启紧急任务开关,单击“确定”按钮,提交一个紧急任务。
算法管理
“业务管理 > 算法管理”,在业务范围是训推、训练下可用
创建算法
用户单击“创建”或“创建版本”,进入创建算法或创建版本页面。用户可以根据需要,填写相关算法信息。
创建算法页面,可以自定义算法名称和版本。创建版本页面,算法名称不能自定义。镜像可以使用平台镜像或者外部镜像。脚本模式需要在个人目录选择算法执行脚本和执行目录,且执行脚本在执行目录下,命令模式需要输入执行命令。 运行参数是执行脚本或命令需要的运行参数,环境变量是算法任务运行需要的环境变量,可以选择性填写运行算法需要的CPU和加速卡资源数量。部署类型,根据镜像框架类型,自主选择。选择模型,可以根据需求选择模型。
支持的部署类型:
| 部署类型 | 框架 |
|---|---|
| 单机(Worker:1) | 所有框架 |
| PS/Worker(PS:1-1000,Worker:1-1500) | tensorflow |
| MPI(Worker:2-1500) | 非paddlepaddle框架 |
| Master/Worker(Master:1,Worker:1-1500) | pytorch |
| Server/Worker(Server:1-1000,Worker:1-1500) | mxnet |
| collective:(Worker:2-1500) | paddlepaddle |
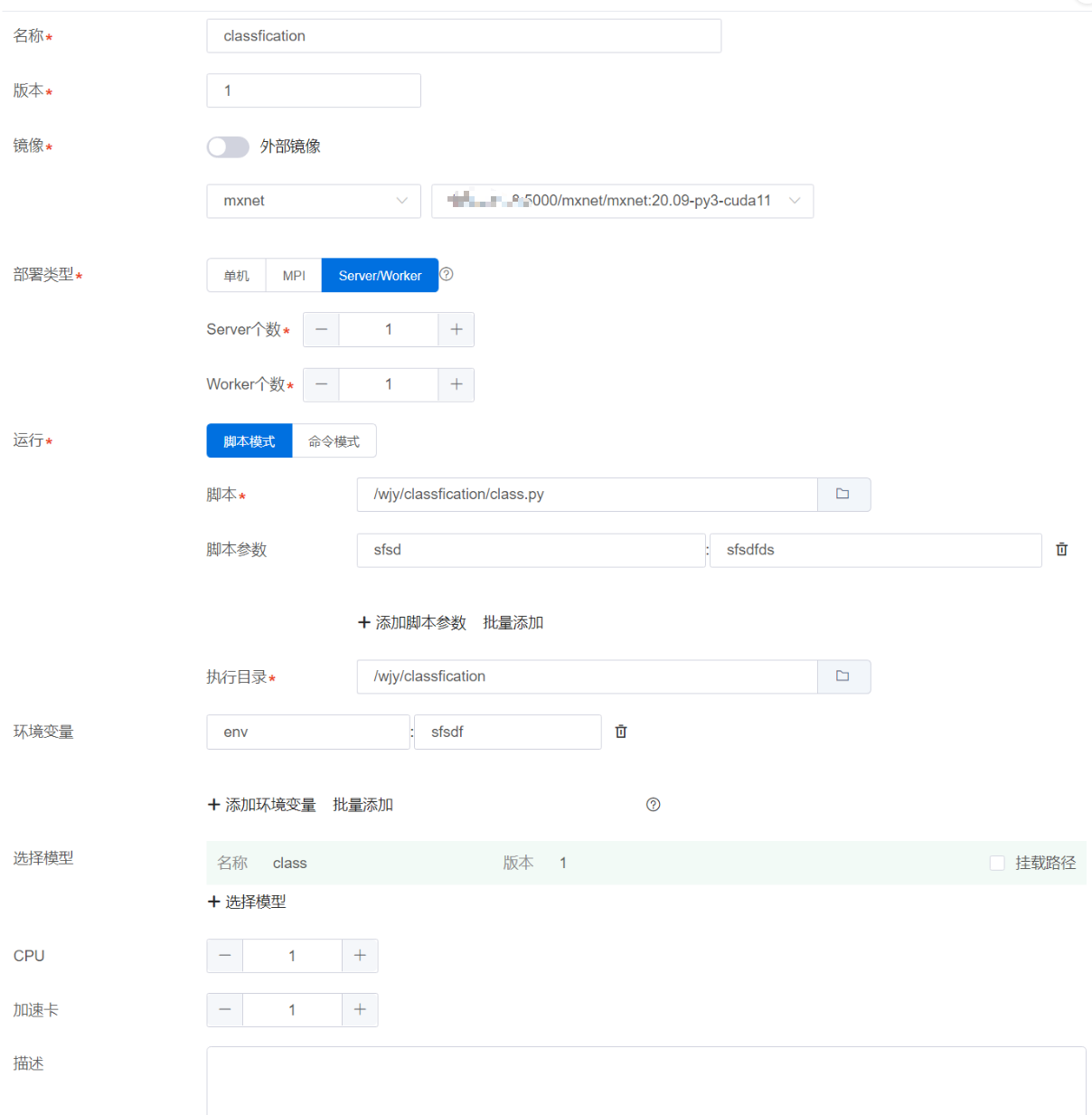
创建算法页面,用户可以使用已发布的算法进行快速创建,单击对应的已发布算法,创建信息会自动填充,用户可以根据需要,进行修改。 脚本模式,如果用户未自己选择脚本和目录,平台会将已发布的算法目录,拷贝到用户个人目录,以创建的算法名称_版本命名。用户自己选择,则不再进行拷贝,以用户选择为准。
弹性任务配置:
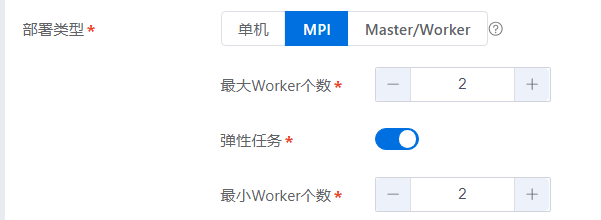
具体操作配置参考“任务管理 > 创建训练任务 > 弹性任务配置”内容
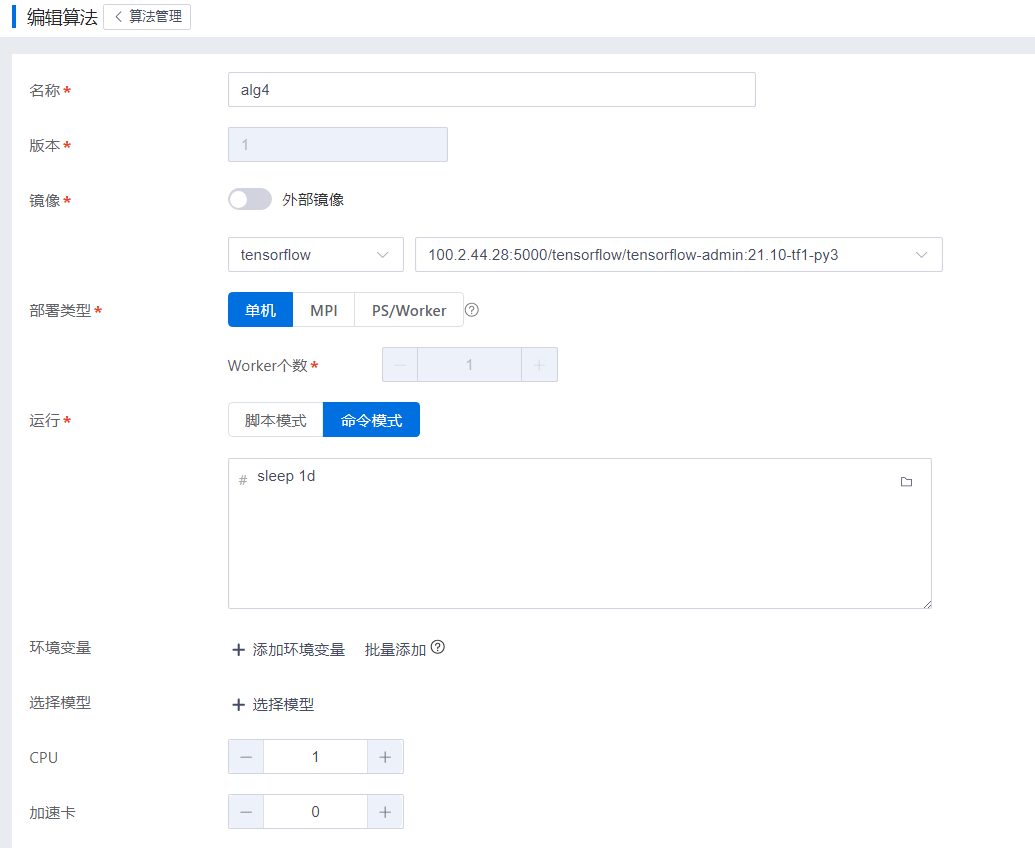
编辑算法
用户单击“编辑”按钮,进入编辑算法界面,除算法名称和版本外,可以根据需要修改相关信息。
算法列表
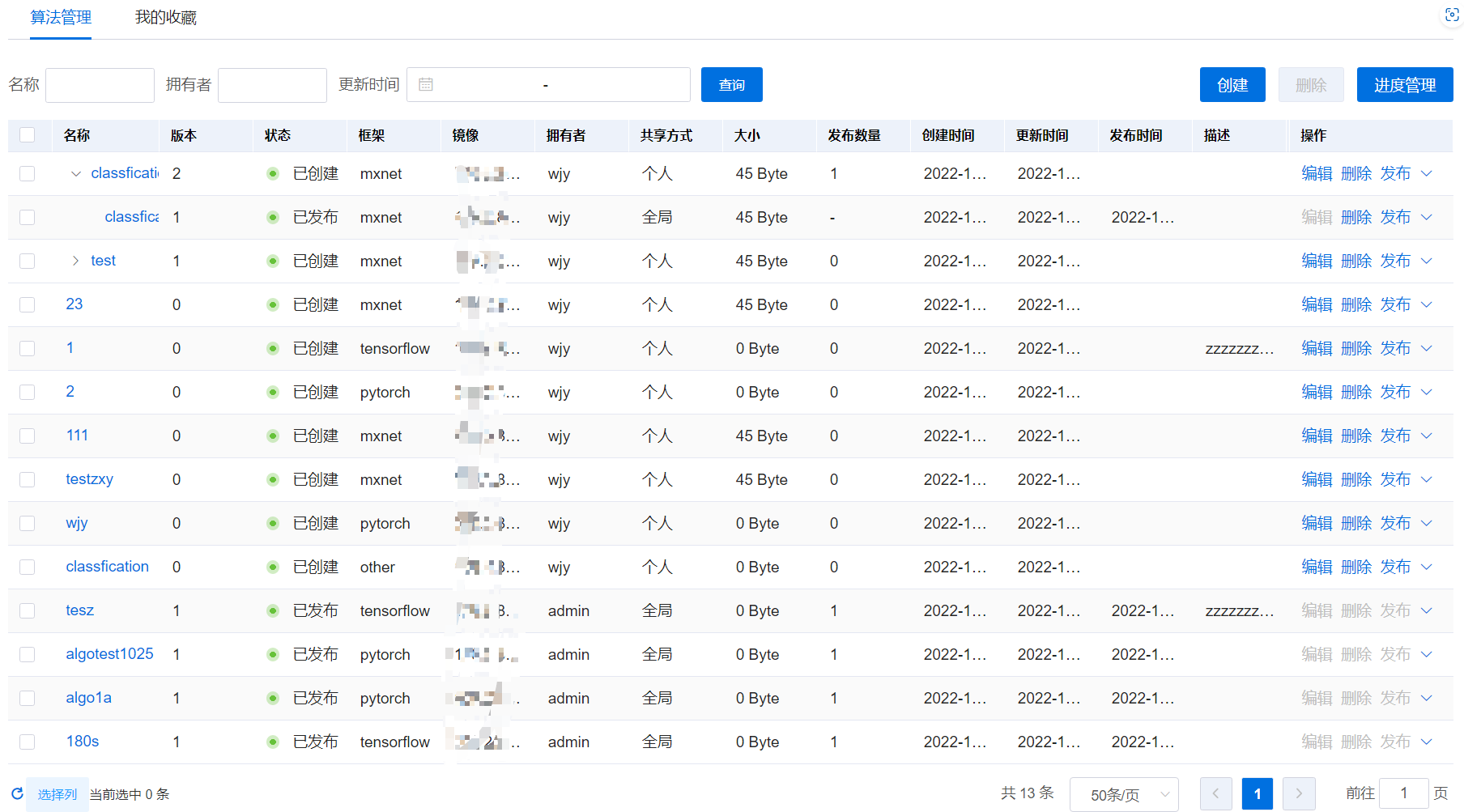
用户单击“算法管理”,显示算法信息主列表,同名算法通过主子列表展示,主列表优先显示最新的算法信息,子列表展示最新的10条数据,用户可查看全局、组内及个人的算法信息。主列表操作栏有修改、删除、训练、发布管理、发布、创建版本、收藏等功能。
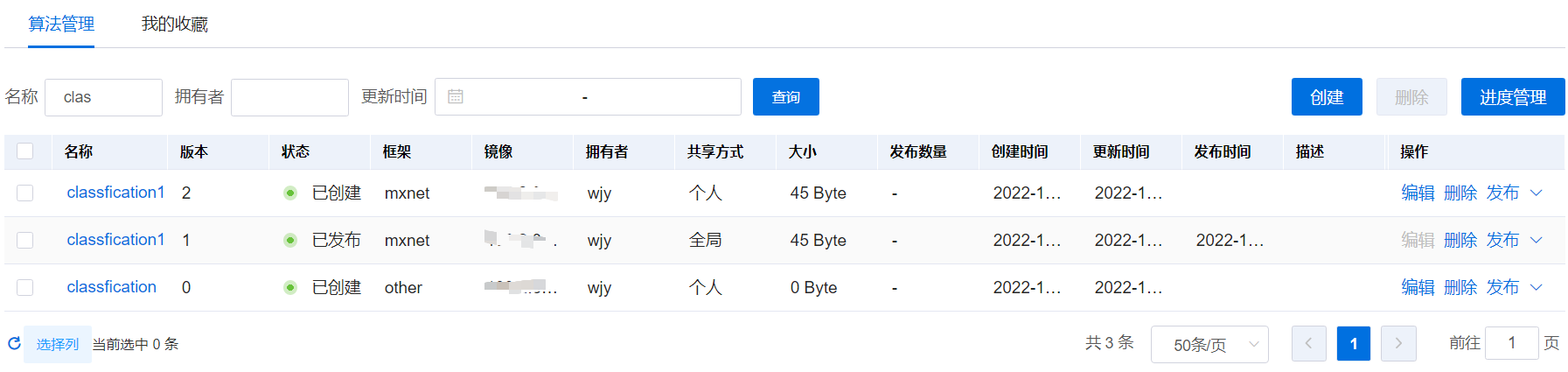
用户可以根据条件查询算法信息,查询条件包括:算法的名称或算法的描述信息、算法的拥有者,以及算法的更新时间范围。根据条件查询的算法信息,不再以主子列表进行展示,而是分页展示符合条件的查询结果。
算法训练
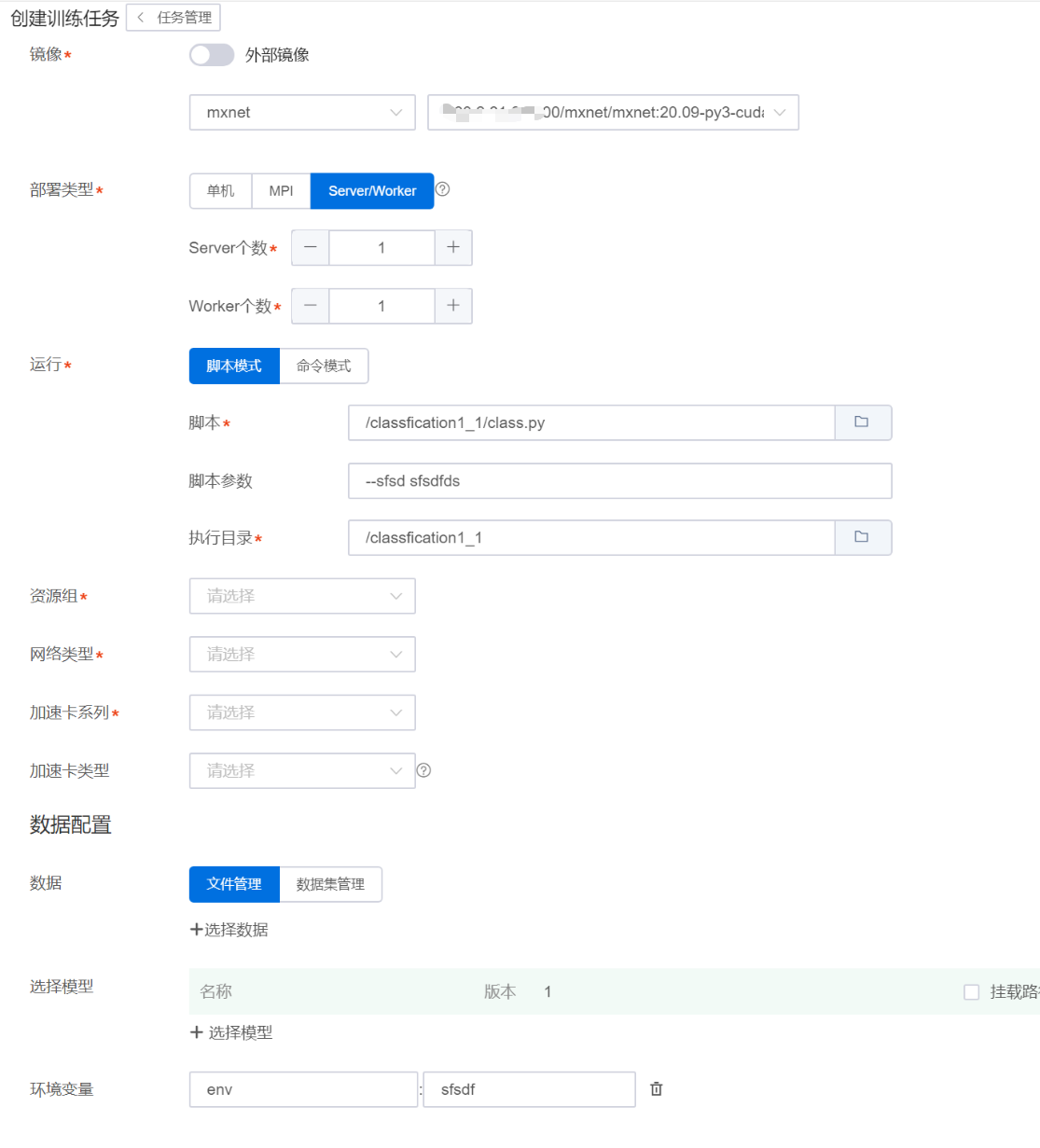
用户单击“训练”按钮,跳转到创建训练任务界面,并自动填充算法相关信息。
发布算法
用户单击发布按钮,可以发布算法,可以将算法发布到个人、组或者全局,发布到组,只有同组成员可以查看,发布到全局,所有用户都可以查看。发布成功后算法状态变为已发布。

算法发布管理
用户单击发布管理按钮或算法名称,进入“发布界面 > 基本信息”界面,可以查看算法的详细信息,单击版本的下拉列表,可以查看同名不同版本的算法详细信息。
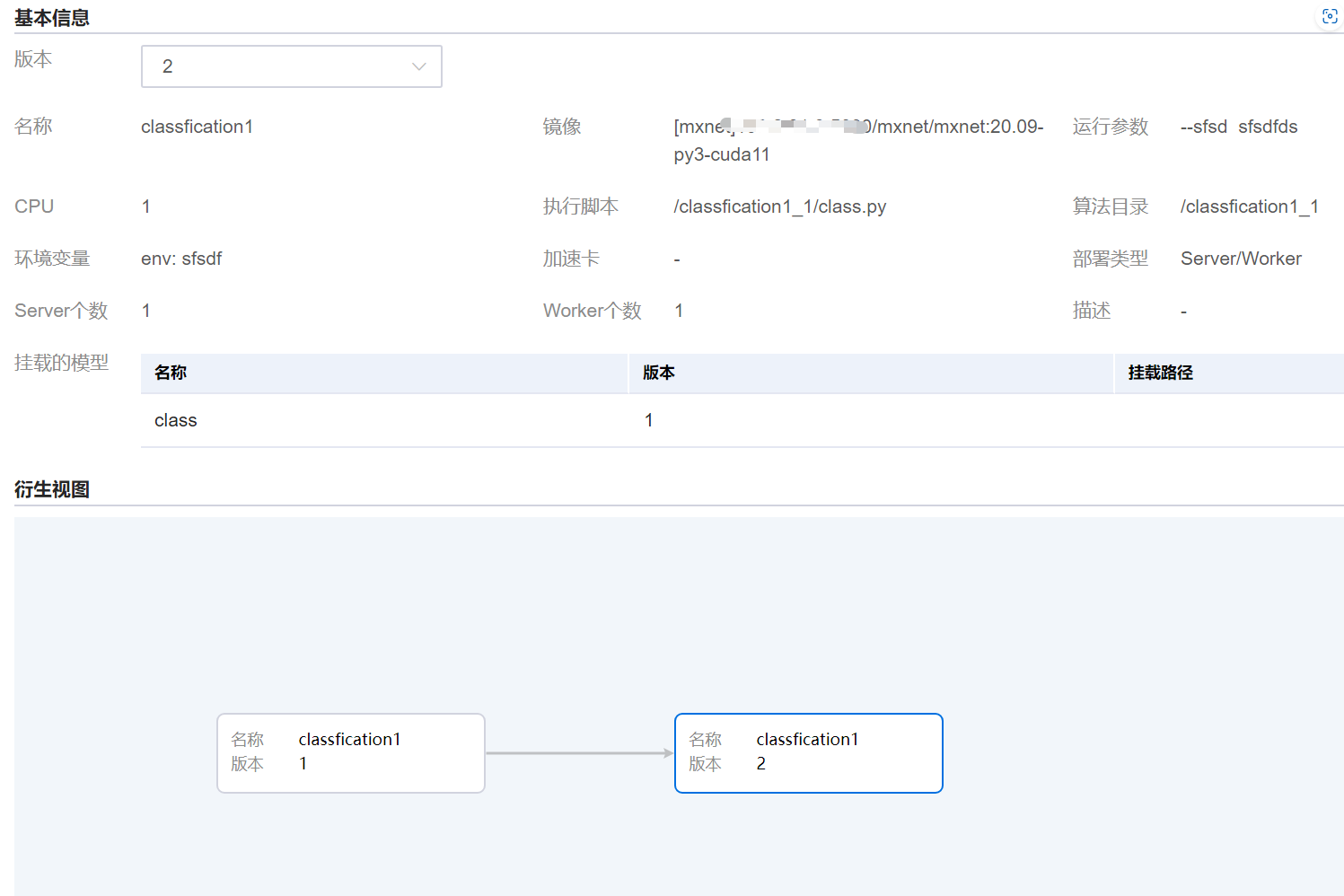
用户在发布界面,单击发布列表,可以查看同名算法的已发布列表,列表操作包含:编辑、删除、训练、发布等。

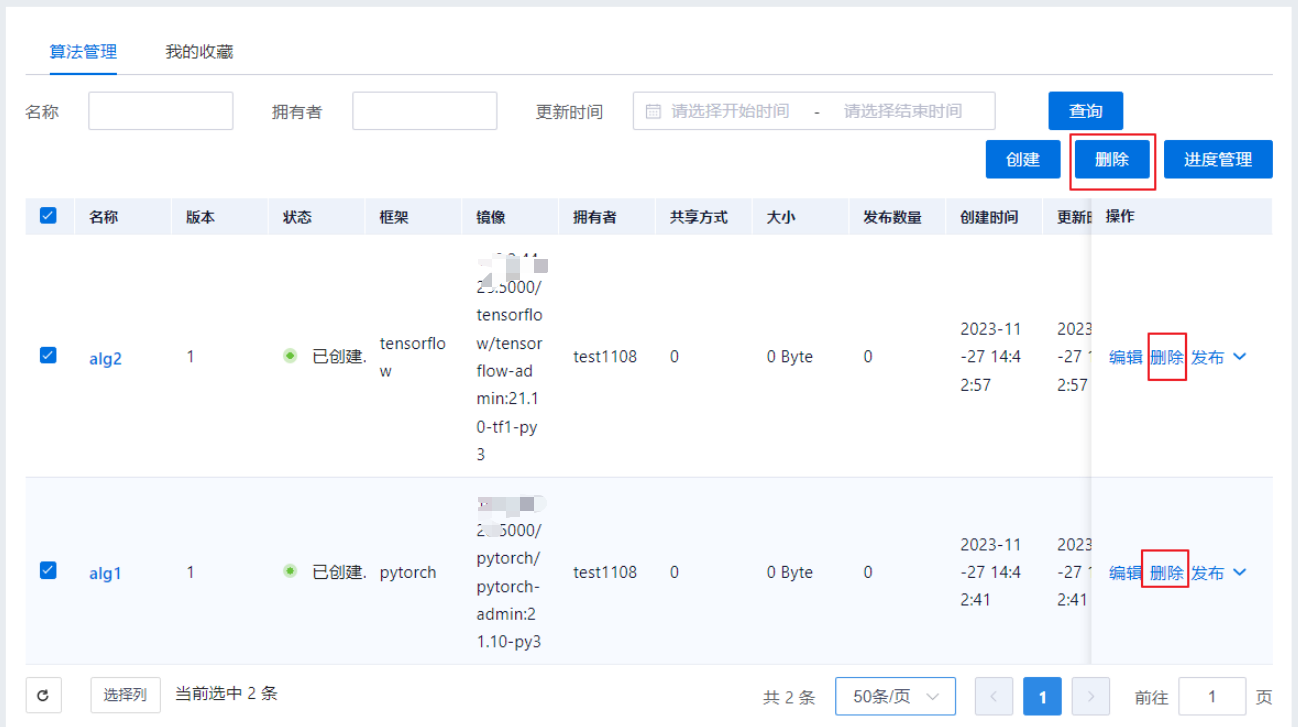
删除算法
用户可以删除符合条件的算法,未发布算法支持批量删除,已发布算法不支持批量删除。
进度管理
进度列表,维护算法相关功能操作的进度信息,其中,一些操作场景是没有进度管理的概念的,比如创建命令模式的算法,没有进度列表。进度列表,主要针对操作算法目录场景。
| 操作类型 | 场景 |
|---|---|
| 操作类型“创建” | 已发布 > 创建算法。 |
| 操作类型“编辑” | 已发布 > 创建 > 创建失败;已创建 > 发布 > 发布失败。 |
| 操作类型“发布” | 已创建 > 发布;已创建 > 发布 > 发布失败 > 发布。 |
| 操作类型“删除” | 已发布 > 删除。 |
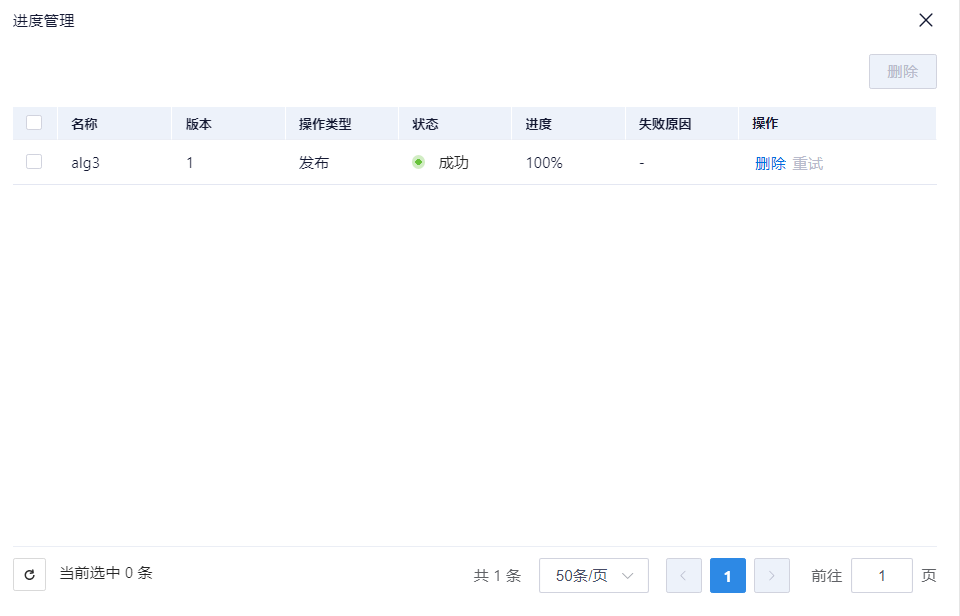
失败重试
进度管理列表,操作类型:创建、编辑和发布失败的进度,如果状态为失败,可以进行失败重试,再次进行操作。
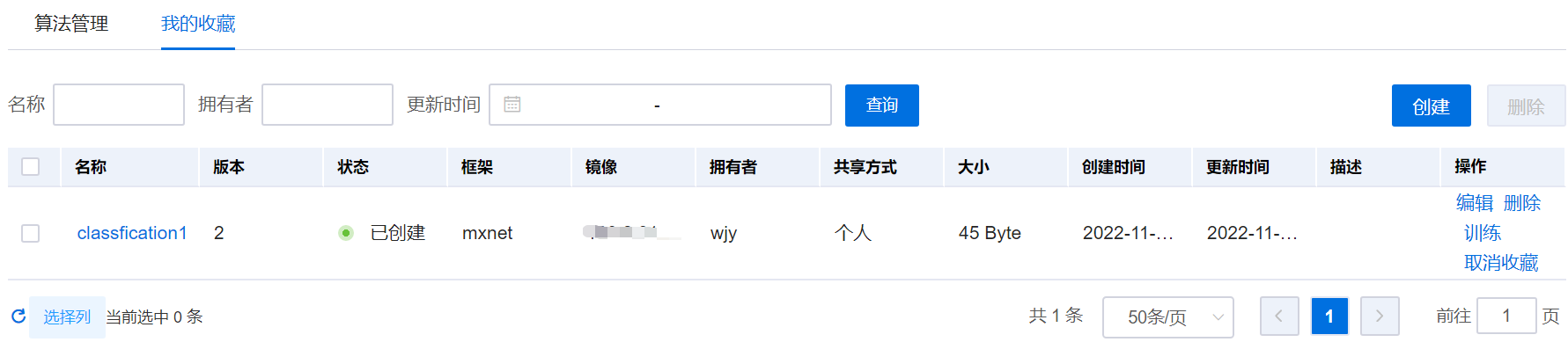
算法收藏和取消收藏
用户可以收藏算法,并在“我的收藏”中,查看收藏的算法,也可以取消收藏的算法。
工作流管理
“业务管理 > 工作流管理”,在业务范围是训推、训练下可用
创建工作流
用户单击“创建”,进入创建工作流页面。用户可以根据需要,自己填写工作流信息。 工作流创建,主要有以下步骤:
1.基本信息
| 字段 | 描述 |
|---|---|
| 名称 | 工作流名称,全局唯一 |
| 定时执行 | 是否开启定时执行,开启后,可以按照年、月、周、日或者自定义cron配置执行周期 |
| 立即运行 | 工作流创建成功是否开启立即运行,如果开启,创建成功后会立即触发工作流运行 |
| 描述 | 工作流的描述信息 |
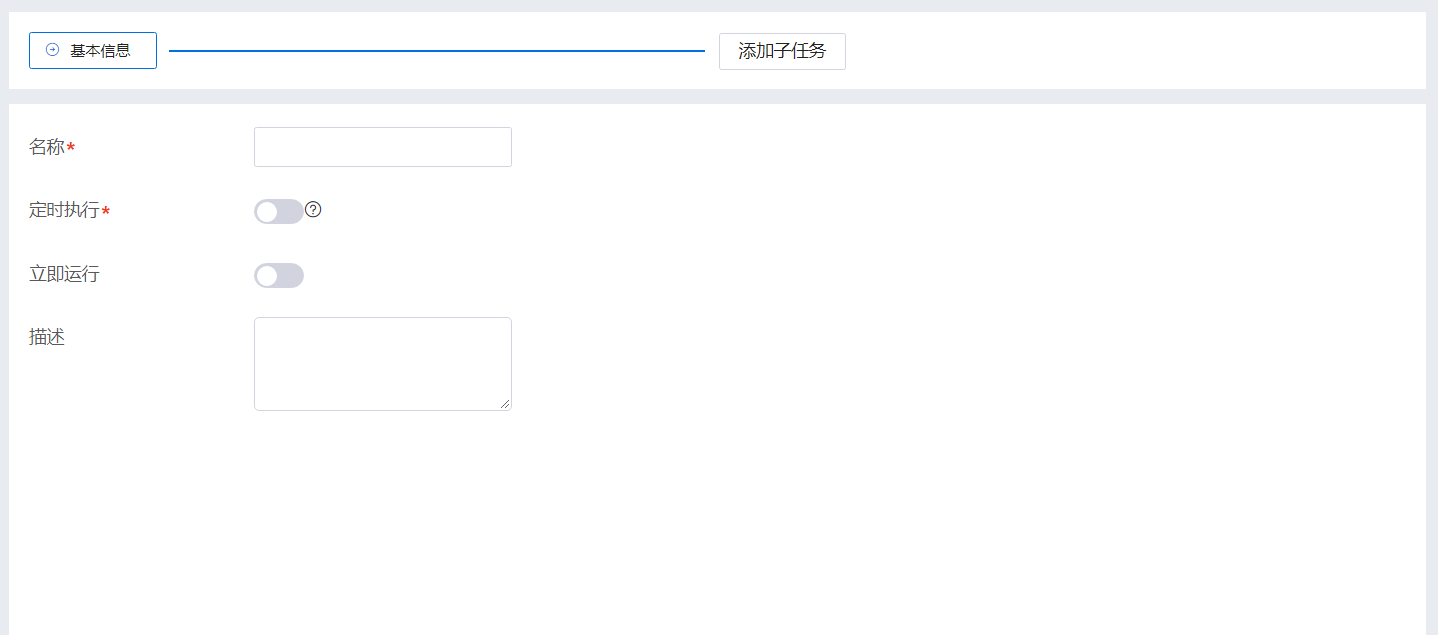
2.子任务(支持多个子任务)
| 字段 | 描述 |
|---|---|
| 任务信息 | 包括“任务名称”字段,工作流子任务的名称。 |
| 资源信息 | 工作流子任务的资源配置,包括“资源组”、“集群网络类型”、“加速卡系列”、“加速卡类型”。 |
| 任务数据 | 工作流子任务的数据配置,包括“数据”信息,用户可以选择子任务需要的数据集信息。 |
| 算法信息 | 工作流子任务使用的算法配置,选择对应的算法后,可以修改算法带入的配置信息,包括脚本参数、环境变量、部署类型、CPU/加速卡等配置。 |
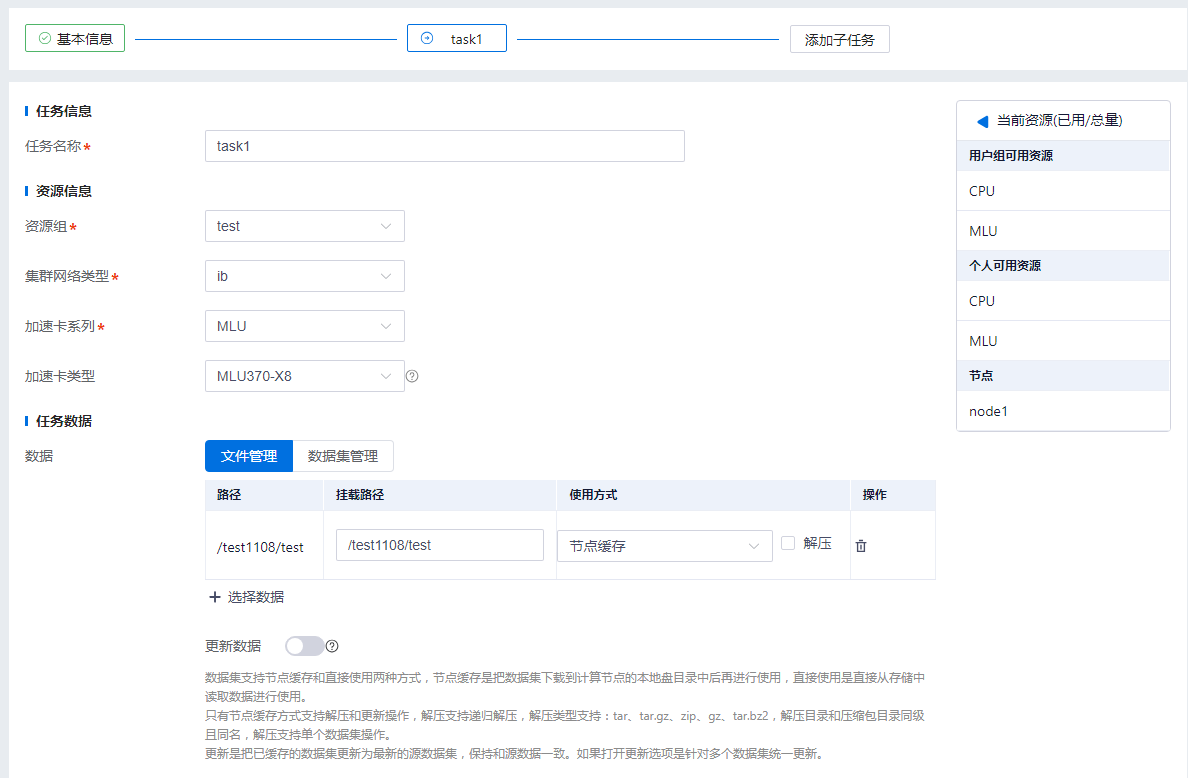
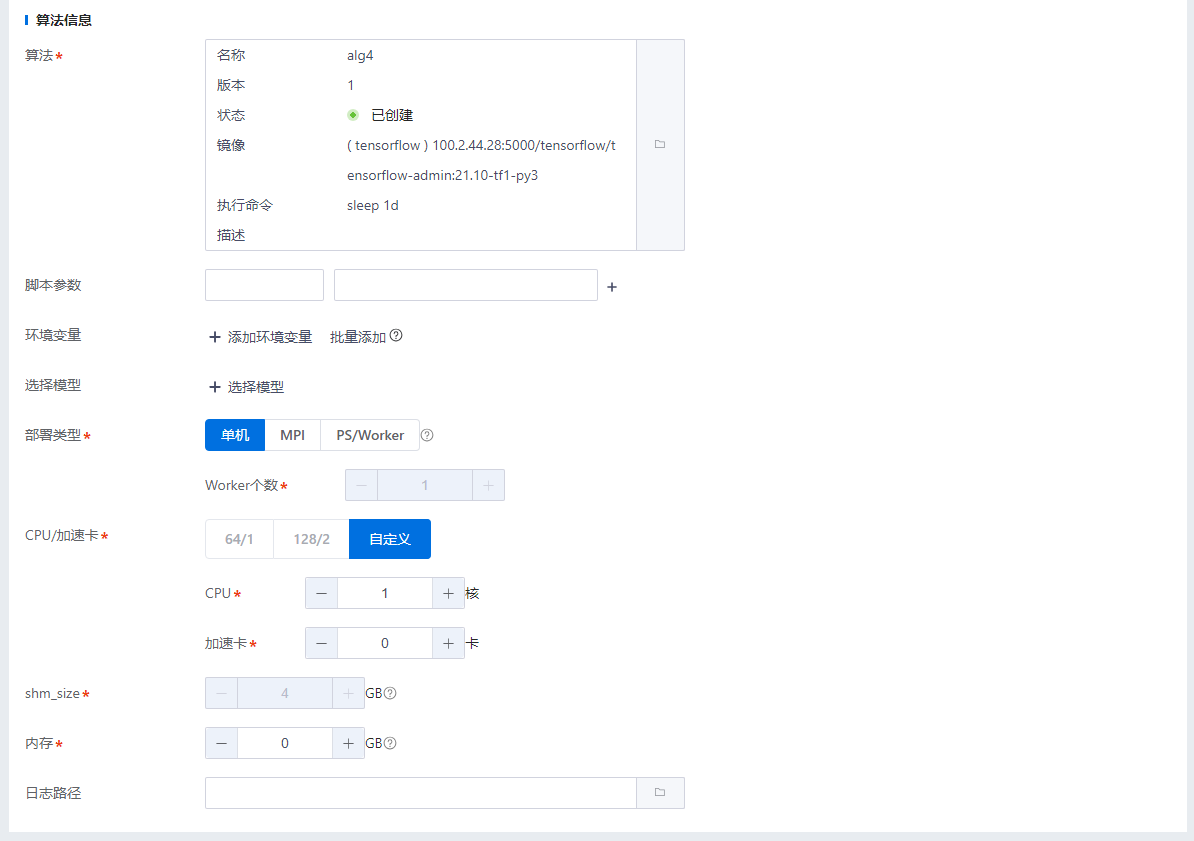
运行工作流

工作流启动方式:
1.立即运行:创建和编辑工作流时设置为立即启动运行,则完成工作流配置后,该工作流会自动立即运行。
2.非立即运行:待创建完成工作流后,在工作流列表操作栏,手动单击“运行”按钮。
3.定时执行:创建和编辑工作流时设置,或在工作流列表上方选择开启定时执行。
停止/启动工作流

用户可以将运行未完结的工作流停止,停止后,工作流任务以及子任务都会停止,同时也不会再执行周期调度。
用户可以启动停止的工作流。
编辑工作流
对符合状态条件的工作流进行编辑,有些信息无法修改,如工作流名称等。
删除工作流
对符合状态条件的工作流进行删除。
工作流信息查看
用户可以选择列表中的工作流,单击工作流名称,进入工作流详情页面,查看工作流基本信息、子任务,以及工作流任务。
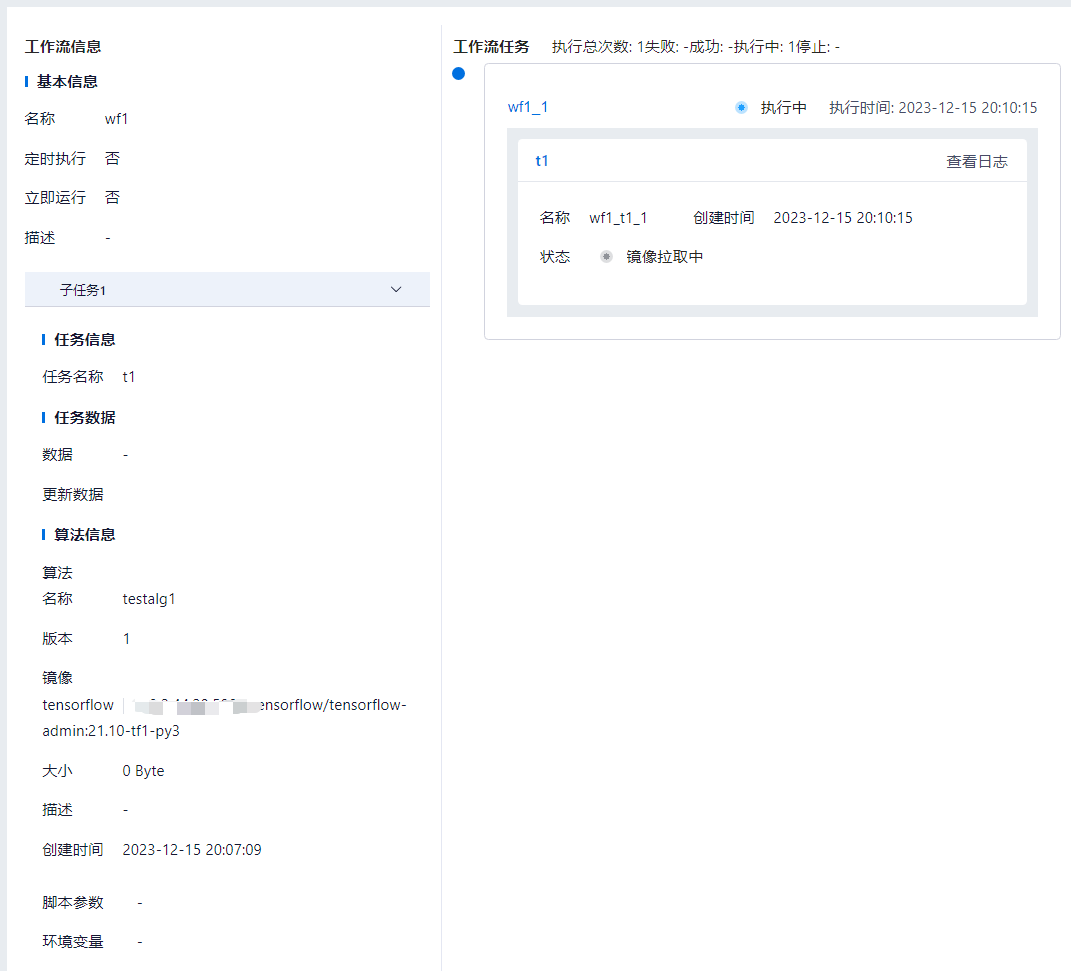
模型管理
“业务管理 > 模型管理”,在业务范围是训练+推理、训练下可用
平台提供了统一的模型管理能力,集中管理在训练任务中得到的模型、用户本地开发的模型、外部平台输出的模型。模型管理提供统一的导入功能入口,可以方便把本地和外部模型导入到模型管理系统中。在模型管理中提供发起测试功能进行模型的测试,测试过程提供详细的日志信息查看,测试完成后提供统一的模型发布功能,为部署模型做准备。
导入模型
在训练任务完成后,平台会自动把模型文件保存到用户家目录中,能够方便地导入模型管理中。
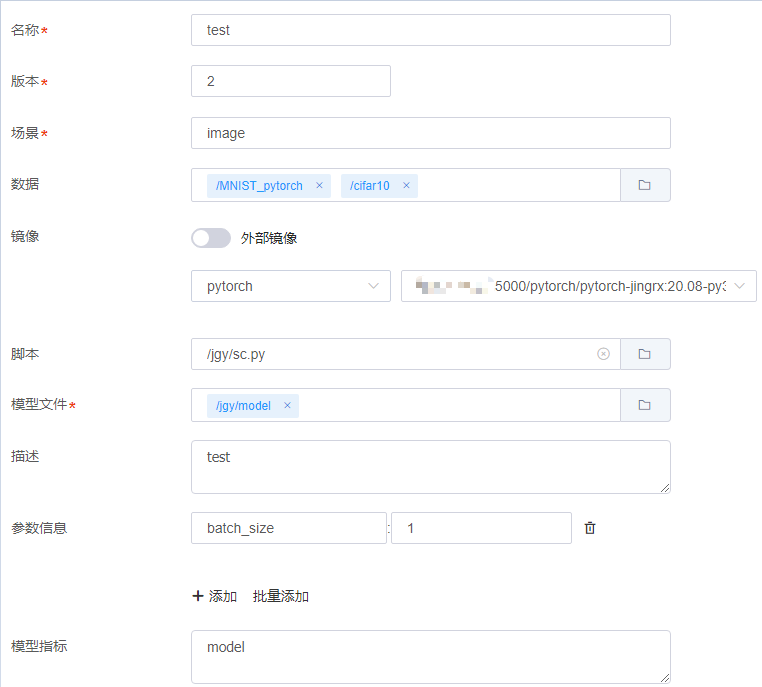
单击“模型管理 > 导入”,进入导入界面。 导入模型需要填写以下信息:
| 名称 | 说明 |
|---|---|
| 名称 | 模型的名称,必填参数,只接受汉字、英文字母、数字、下划线, 不能以下划线开头 |
| 版本 | 模型的版本,必填参数,整数 |
| 场景 | 模型的场景,必填参数 ,自定义输入 |
| 数据 | 记录模型使用的数据,非必填 |
| 镜像 | 记录模型使用的镜像,非必填 |
| 脚本 | 记录模型使用的脚本,非必填,只可以选择以.py和.prototxt结尾的脚本文件 |
| 模型文件 | 导入的模型文件,必填参数, 选择用户家目录下的模型文件,只能选择单个目录且不为空目录 |
| 描述 | 模型的描述,非必填 |
| 参数信息 | 模型的参数,非必填,以键值对key和value方式进行输入,支持批量输入 |
| 模型指标 | 模型的指标,非必填,自定义输入 |
示例中用户选择的文件为本次训练任务中得到的模型文件。

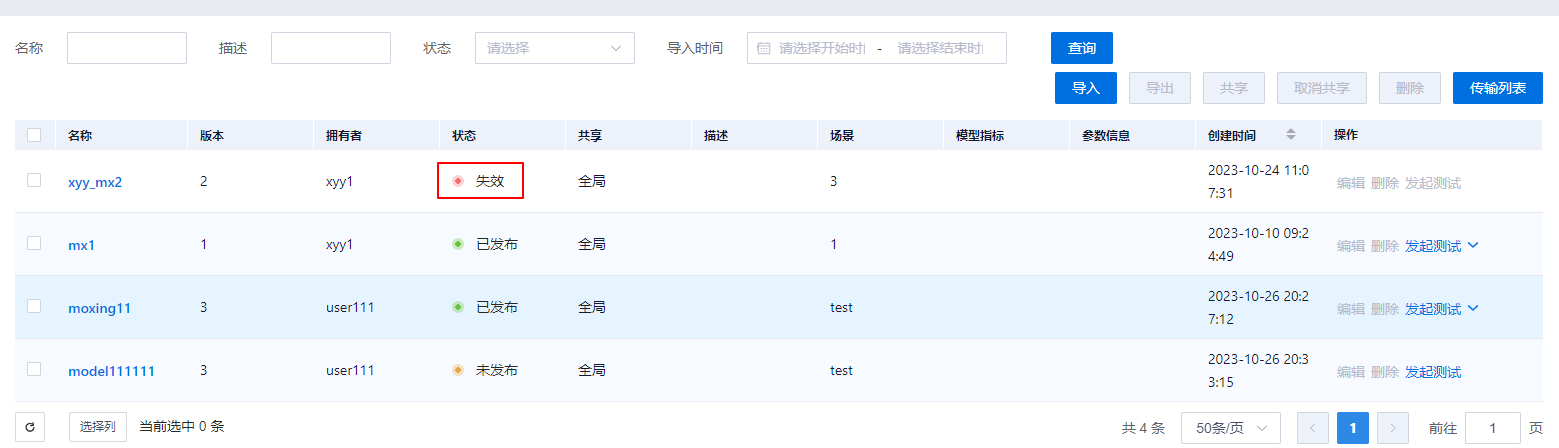
单击“确定”后,将模型导入到模型管理中,该模型文件在文件管理中显示一个共享图标,区别其他普通的文件。如果该模型文件在文件管理被删除,等待一个定时5分钟的周期后,该模型状态会变为失效。
共享模型
模型的共享属性有三种:私有、组、全局。
普通用户单击“模型管理”,普通用户可以共享私有和自己组内模型。
选择要共享的模型,单击右上方“共享”按钮,支持批量操作。

取消共享
取消共享操作和模型共享操作互逆。
普通用户单击“模型管理”,可以将自己共享到组或全局的模型取消共享。支持批量操作。

删除模型
普通用户单击“模型管理”,普通用户可以删除拥有者是自己的模型。支持批量操作。

导出模型
普通用户在“模型管理”中,选中要导出的模型,单击导出按钮,并在弹出框中自定义tar包名称,导出模型tar包至用户家目录下。



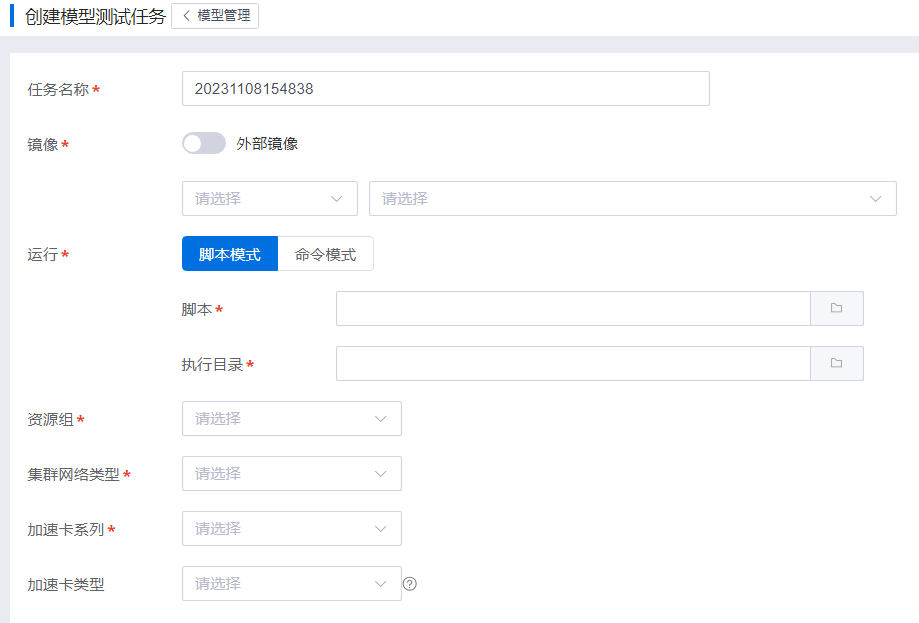
模型测试
用户选择模型发起测试,创建模型测试任务。

发布模型
普通用户默认没有发布权限,需要管理员通过用户管理界面,单击“用户管理 > 用户 > 配额权限信息 > 调整权限”开启模型发布,赋予该用户模型发布的权限。
赋权后,该普通用户需要重新登录。单击“模型管理”,选中要发布的模型,单击发布按钮。

若页面上方提示“该操作需要等待管理员审批,审批结果可在审批管理中查看”,则需要管理员进行审批操作。若管理员审批通过,该模型正常发布;若管理员审批拒绝,则该模型不进行后续发布操作 。

导入应用
发布后的模型,可以进行导入应用操作。

对于训推融合场景,且用户业务范围包括训练和推理,自动跳转到应用商店导入应用页面,将模型token自动带入到输入框中。
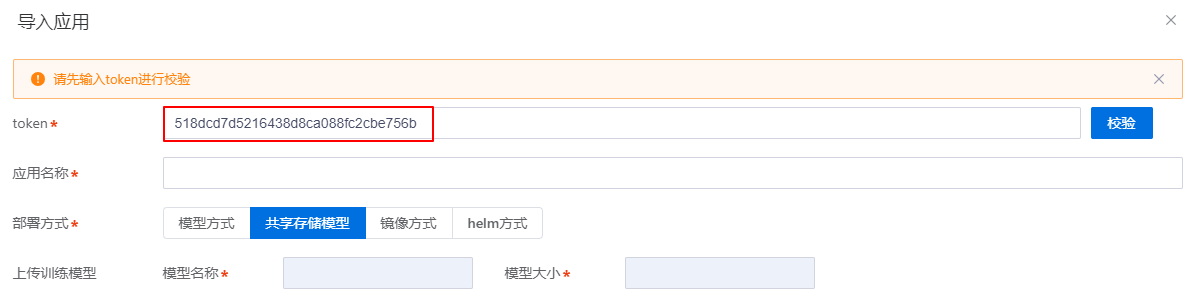
对于其他场景,单击导入应用后,弹框提示token值。

模型传输列表
进入传输列表的操作为:导出模型。同一用户导出操作进行排队。
对于模型较大的文件,可以展示操作进度。对于完成、失败、排队的进度,可以单击“删除”按钮逐条删除。进行中的进度无法删除。
模型列表
可以根据名称、描述、状态、导入时间查询模型列表。
| 查询条件 | 说明 |
|---|---|
| 名称 | 全模糊查询 |
| 描述 | 全模糊查询 |
| 状态 | 下拉框中选择模型状态的精确查询 |
| 导入时间 | 选择起止时间查询 |
模型列表列包括:名称、版本、拥有者、状态、共享、描述、场景、模型指标、参数信息、创建时间、操作。可以根据创建时间进行升序或降序排列。

名称相同,版本不一样时,会折叠展示。

编辑模型
选择模型列表中的一个模型,单击编辑按钮,输入要更改的模型信息,单击确定。
